
弗利克/马克·范德沃在构建安全系统时,拥有随机数的来源是至关重要的。没有它们,大多数密码系统都会崩溃,双方通信的隐私性和真实性可能会被破坏。例如,如果您正在使用指向https://blog.cloudflare.com然后,您使用的SSL连接将需要随机数来确保其安全性(它们被用作建立安全连接的一部分)。我们在之前的博客文章中已经讨论过为什么安全系统需要随机数,但是从计算机中获取随机数是非常困难的。这篇博客文章介绍了Linux的内部随机数生成器,以及它如何克服在一台非随机机器上生成随机数的问题。CloudFlare的服务器需要一个良好的随机数来源来进行身份验证,并确保SSL中的完全前向保密性。但是,从内部来看,我们使用的计算机都是确定性机器,它们遵循指令,并且必须以可预测的方式进行操作。不确定性和不可预测性并不是天生的:要告诉计算机去掷硬币或掷骰子是不容易的。要想在计算机中获得随机性,必须在外部世界中寻找。消费类计算机和移动设备有许多传感器,它们提供不可预测的输入。如果足够仔细地测量,用户的按键和鼠标移动的时间会有一定程度的随机性。麦克风和摄像机发出的噪音也会带来很大的随机性。移动设备有更多的来源,包括波动的wifi信号、运动传感器和GPS信息。大多数传感器在最需要随机数的服务器上不可用。对于在可能无法访问精确系统时钟的虚拟化环境中运行的服务器,这一点尤其如此。对于CloudFlare的服务器,我们目前依赖于Linux操作系统中内置的随机数生成器。Linux是世界上最流行的操作系统之一。从世界上许多大型网站(谷歌、Facebook、亚马逊、苹果等)的网络服务器和数据中心,到台式电脑(Ubuntu、Chrome OS等),再到嵌入式设备(智能电视、Android等),它都可以作为操作系统。CuldFLARE软件是在Linux操作系统内核的基础上构建的。Linux本身提供了随机数服务,因此任何程序都可以随时访问随机数。幸运的是,Linux是开源软件,我们可以通过阅读代码来了解它的工作原理。并验证它为我们的加密目的提供了一个合适的随机数来源。熵与随机性并非所有的随机性都是一样的。有两种随机性需要考虑:一致性和不可预测性。如果运行足够长的时间,所有的数字都会出现相同的频率,那么随机数生成器将提供"统一"的输出。这对于建模随机进程很有用,但对于安全性来说还不够好。对于计算机安全,随机数必须难以猜测:它们必须是不可预测的。数字的可预测性是用一种叫做熵的度量来量化的。如果掷一枚公平的硬币,它会提供一点熵:硬币正面或反面的概率相等(可以认为是0和1)。因为概率是相等的,所以硬币的"输出"是不可预测的。我们说它提供了一点熵。不公平的掷硬币只提供不到一个比特,因为当你知道偏见的时候就更容易猜测了。掷硬币的两面都有头像,没有熵,因为掷硬币的结果可以完全肯定地猜到。熵不同于统计随机性。观察数字流的统计特性并不能保证该流包含任何熵。例如,pi的数字在几乎任何统计度量下看起来都是随机的,但是不包含熵,因为有一个众所周知的公式可以计算它们并完美地预测下一个值。(顺便说一句,pi是一个普通数的例子:所有的数字都将以相等的数量出现)。

Flickr/foxtangle许可证:CC Attribution 2.0 Generic而且,大数并不总是具有高熵。你可以取一个小的随机数,把它变成一个大的随机数,熵保持不变。例如,取一个从1到16的随机数,用SHA-1这样的算法计算它的密码散列。得到的160位数字看起来非常随机,但它只是16个可能的数字中的一个。猜这个数字就像猜一个从1到16的随机数一样简单。重要的是从中抽取随机数的池的大小。对于加密密钥,用于创建它们的熵量与它们的难猜性有关。从具有20位熵的源创建的128位密钥并不比20位密钥更安全。创建安全密钥需要一个良好的熵源。在游泳池里泡一泡在Linux上,所有随机性的根源是被称为内核熵池的东西。这是一个大的(4096位)的数字,在内核的内存中被秘密保存。这个数字有24096种可能性,因此它可以包含多达4096位的熵。有一个警告-内核需要能够用4096位的熵从源中填充内存。这就是最难的部分:找到那么多的随机性。熵池有两种使用方式:从中产生随机数,并由核用熵来补充。当随机数从池中生成时,池的熵会减小(因为接收随机数的人对池本身有一些信息)。因此,当随机数被分发时,池的熵减小,池必须被补充。补充池称为搅拌:新的熵源被搅拌到池中的混合比特中。这是Linux上随机数生成如何工作的关键。如果需要随机性,则从熵池中导出。当可用时,其他随机性来源被用来搅动熵池,使其不那么可预测。这些细节有点数学化,但是理解Linux随机数生成器的工作原理和技术应用于其他软件和系统中的随机数生成时是如何工作的很有趣。内核对池中熵的位数进行了粗略的估计。您可以通过以下命令检查此估计值:cat/proc/sys/kernel/random/熵可用一个拥有大量可用熵的健康Linux系统将获得接近4096位熵的回报。如果返回的值小于200,则系统的熵不足。内核在看着你我提到过,系统采用其他随机性来源,并用它来搅动熵池。这是通过使用时间戳来实现的。大多数系统都有精确的内部时钟。每次用户与系统交互时,该时间的时钟值被记录为时间戳。尽管年、月、日和小时通常是可猜的,但毫秒和微秒是不可猜的,因此时间戳包含了一些熵。从用户的鼠标和键盘获得的时间戳以及来自网络和磁盘的时间信息具有不同的熵量。时间戳中的熵是如何被转移到熵池中的?简单,用数学来混合。好吧,如果你喜欢数学就简单。把它混在一起就行了熵的一个基本性质是它混合得很好。如果你把两个不相关的随机流合并起来,新的流的熵不会更小。取一些低熵源并将它们组合在一起可以得到一个高熵源。所需要的就是正确的组合函数:一个可以用来组合两个熵源的函数。最简单的逻辑函数是异或。这个真值表显示了来自不同随机流的位x和y是如何通过XOR函数组合的。
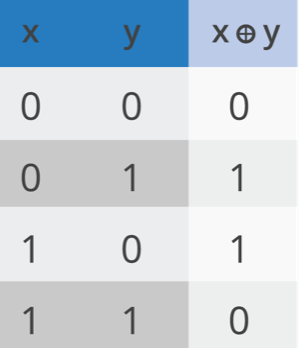
即使一个比特源没有太多的熵,将其异或到另一个源也没有坏处。熵总是增加。在Linux内核中,使用xor的组合将时间戳混合到主熵池中。生成随机数密码应用需要非常高的熵。如果生成的128位密钥只有64位的熵,则可以在264次尝试中猜测,而不是2128次尝试。这就是需要一千台计算机运行几年来强行破解密钥与需要所有的计算机运行超过宇宙历史的时间之间的区别。加密应用程序需要接近每比特一位的熵。如果系统的池的熵小于4096位,那么系统如何返回一个完全随机的数字?一种方法是使用加密哈希函数。加密哈希函数接受任何大小的输入并输出固定大小的数字。改变一位输入将完全改变输出。散列函数擅长将事物混合在一起。这种混合特性将熵从输入均匀地传播到输出。如果输入的熵大于输出的大小,那么输出将是高度随机的。这就是高熵随机数是如何从熵池中导出的。Linux内核使用的哈希函数是标准的SHA-1加密哈希。通过散列整个池和一些附加的算法,系统将创建160个随机位供系统使用。当这种情况发生时,系统会相应地降低池中熵的估计值。上面我说过,如果池中没有足够的熵,应用SHA-1这样的散列可能会很危险。这就是为什么保持一个ey是至关重要的
版权声明:本文发布于收集站云 内容均来源于互联网 如有侵权联系删除





